Computational biology
- Computational biology
- An amorphous term that encompasses any application of computational methods to obtain insight into biological phenomena.
This is intentionally broad because I could not find a more specific description that everyone agreed on. Wikipedia defines it as
the use of data analysis, mathematical modeling, and computational simulations to understand biological systems and relationships.
This is derived from an NIH document from more than 24 years ago and is still relevant today. Scopes of scientific journals for computational biology are another way we could define the field. The Journal of Computational Biology establishes its scope as
the development and application of new methods in computational biology, including algorithmic, statistical, mathematical, machine learning, and artificial intelligence contributions.
and PLOS Computational Biology as contributions that
further our understanding of living systems at all scales—from molecules and cells to patient populations and ecosystems—through the application of computational methods.
Two subfields
This is my interpretation of computational biology. You will probably get 20 different answers if you ask 20 different people.
Bioinformatics
Bioinformatics is an interdisciplinary field that combines biology, computer science, and statistics to manage, analyze, and interpret biological data. At its core, bioinformatics harnesses computational tools and methodologies to address the challenges posed by the ever-expanding datasets within the life sciences. In practical terms, bioinformatics acts as an essential toolbox; offering scientists the means to navigate, comprehend, and extract insights from biological data. Its significance becomes evident in the identification of concealed patterns, intricate relationships, and insights that may remain elusive through conventional observation alone.
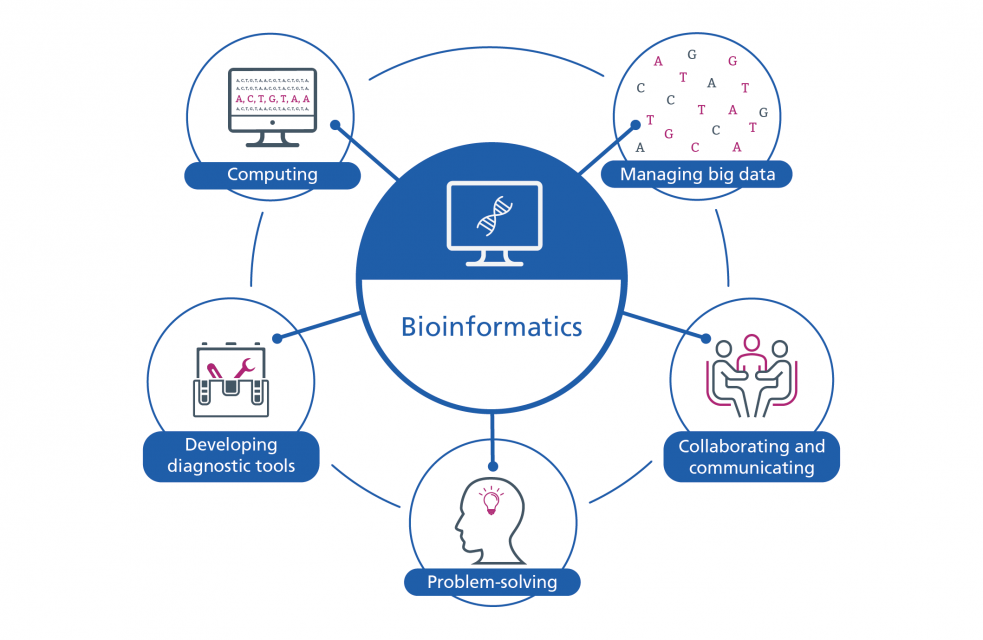
One of bioinformatics’ prominent applications lies in the comparative analysis of genetic sequences across diverse organisms. This capability enables researchers to uncover evolutionary connections, shedding light on the underlying genetic relationships among species. Additionally, bioinformatics plays a pivotal role in drug discovery by identifying potential targets and aiding in the rational design of pharmaceutical compounds; the systematic approach of bioinformatics proves instrumental in unraveling the intricacies of biological data, offering a structured pathway for scientific inquiry.
The advent of high-throughput technologies has propelled the generation of massive datasets, further emphasizing the need for sophisticated bioinformatics tools. These tools are designed not only to handle the volume of data but also to extract meaningful insights from it. Bioinformatics has become an indispensable tool in the life sciences, enabling researchers to make sense of the vast amounts of biological data generated by modern technologies.
Computational structural biology
Computational structural biology is a field that harnesses the power of computational methods to unravel the complexities of biological macromolecules, particularly proteins and nucleic acids. At its core, this discipline seeks to understand, predict, and analyze the structures of these molecules, providing crucial insights into their functions and interactions within biological systems.
One of the primary focuses of computational structural biology is protein structure prediction. This challenging task involves determining the three-dimensional structure of a protein based solely on its amino acid sequence. Researchers employ a variety of methods, ranging from homology modeling, which utilizes known structures of similar proteins as templates, to ab initio prediction, which attempts to predict structures from scratch using physical and chemical principles. Recent years have seen remarkable advancements in this area, notably with the development of AlphaFold3, a deep learning-based approach that has achieved unprecedented accuracy in protein structure prediction, often rivaling experimental methods.
Another key area of computational structural biology is molecular dynamics simulations. These sophisticated computational techniques model the physical movements and interactions of atoms and molecules over time. By simulating the behavior of biological molecules in atomic detail, researchers can gain valuable insights into crucial processes such as protein folding, conformational changes, and molecular interactions. These simulations can reveal the dynamic nature of biological systems, capturing fleeting intermediate states and transitions that are often challenging to observe experimentally. Additionally, techniques like normal mode analysis complement these simulations by revealing large-scale motions of biomolecules, providing a broader perspective on molecular behavior.
Protein-ligand docking is another critical application of computational structural biology, particularly in the realm of drug discovery and development. This method aims to predict the optimal binding orientation of a small molecule (ligand) to its target protein. By simulating these interactions, researchers can screen vast libraries of potential drug candidates in silico, significantly accelerating the drug discovery process. Moreover, docking simulations provide detailed insights into the molecular mechanisms of drug action, helping researchers understand how drugs interact with their targets and potentially leading to the design of more effective and specific therapeutic agents.
Integrative modeling represents a powerful approach in computational structural biology that bridges the gap between computational predictions and experimental data. This method combines information from various experimental sources, such as X-ray crystallography, nuclear magnetic resonance (NMR) spectroscopy, and cryo-electron microscopy, with computational techniques to model complex biological assemblies. By integrating diverse data types, researchers can overcome the limitations of individual experimental methods and construct more comprehensive and accurate models of biological structures. This approach is particularly valuable for studying large macromolecular complexes or dynamic systems that are challenging to characterize using a single experimental technique.
The field of computational structural biology continues to evolve rapidly, driven by advancements in algorithms, increased computational power, and the integration of machine learning techniques. As our understanding of biological systems deepens and experimental methods generate ever-larger datasets, computational approaches become increasingly essential for interpreting and synthesizing this wealth of information. By providing a powerful complement to experimental methods, computational structural biology offers insights that are often difficult or impossible to obtain through experiments alone, paving the way for new discoveries and innovations in biology and medicine.
Specific applications
Protein structure prediction
Accurate protein structure prediction is a crucial aspect of understanding biological systems, as it provides insights into protein functions, drug design, and disease mechanisms. This predictive capability plays a pivotal role in rational drug design by identifying binding sites and facilitating the development of targeted therapies.
Figure 2
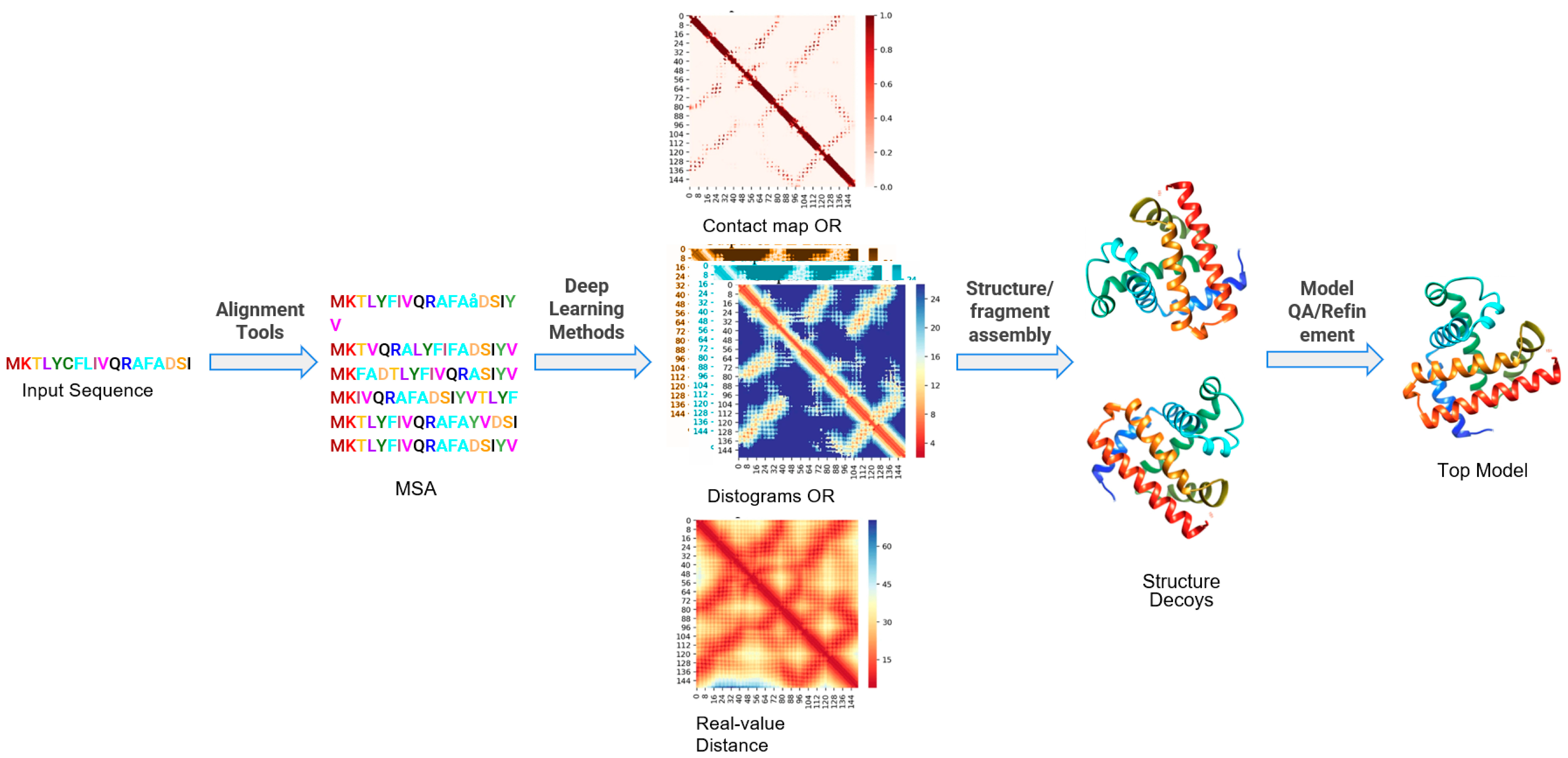
General schematic of template-free protein structure prediction pipeline. Most of the successful existing pipelines for protein structure prediction have these important steps: (i) generation of multiple sequence alignment (MSA), (ii) contact map prediction, distogram prediction or real-value distance prediction, (iii) structure/fragment assembly, and (iv) QA/refinement. Credit: 10.3390/ijms22115553
The ability to predict protein structures accurately has been a long-standing challenge in the field of structural biology. However, recent advances in machine learning models have made significant strides towards achieving this goal. For instance, AlphaFold2 (AF2) and RoseTTAFold are two groundbreaking models that offer computational methods capable of producing protein structure predictions. This software uses deep learning to quickly and accurately predict protein structures based on limited information, which can save years of laboratory work to determine the structure of just one protein. These models have also been successfully used to predict interactions between multiple chains or complexes.
Alternatively, de novo folding is a protein folding method that primarily relies on predicting the three-dimensional structure of a protein from its amino acid sequence without leveraging known structural templates. This process involves understanding the physical principles governing protein folding and the interactions between amino acid residues.
Drug development
In drug discovery, computational biology guides the entire process from target identification to the selection of lead compounds. Harnessing the power of computational methods, researchers can predict the behavior of molecules and forecast their interactions within the complex milieu of the human body. This predictive capability proves pivotal in several aspects of drug discovery, notably in virtual screening.
Figure 3
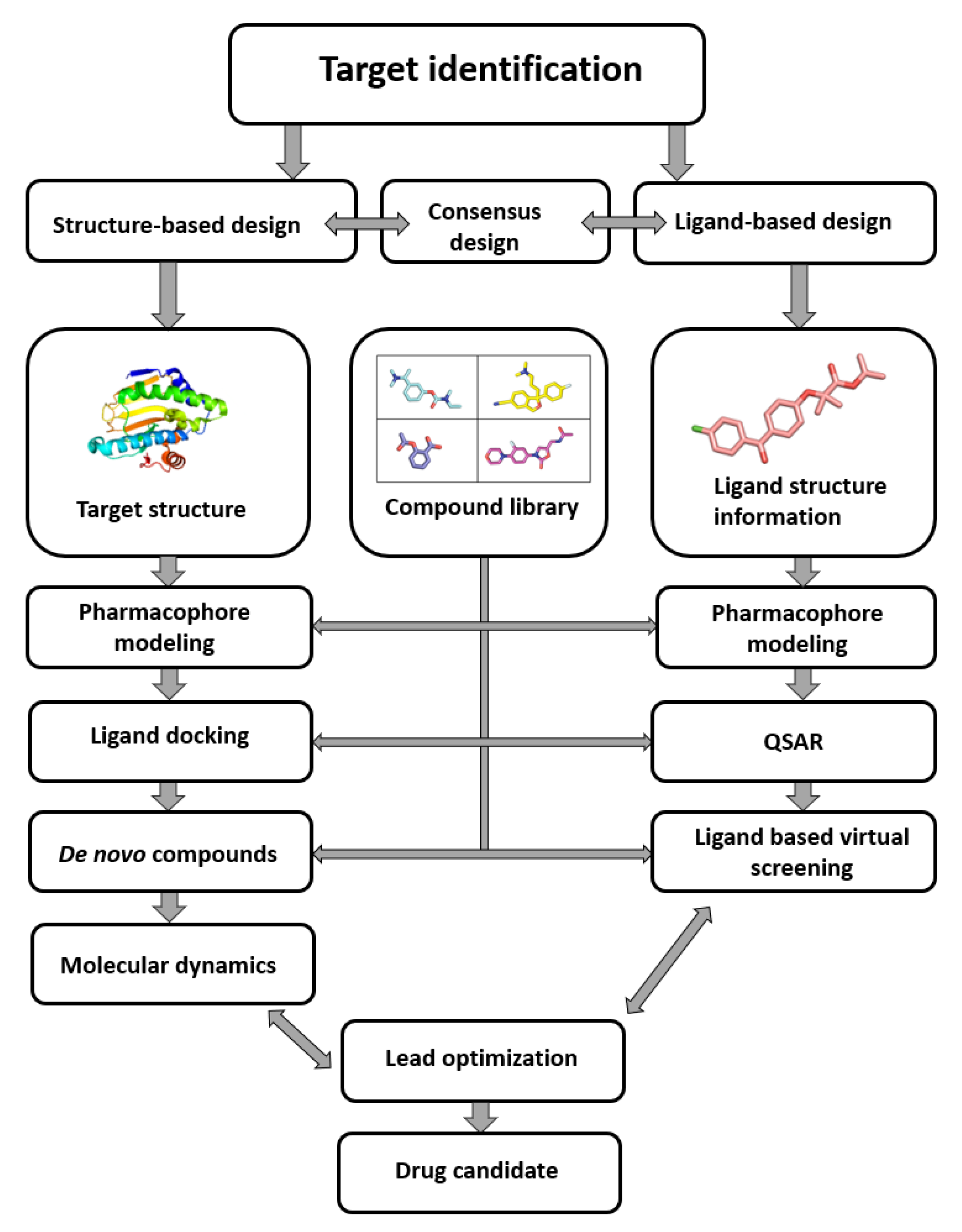
Computer-aided drug design process chart used to obtain lead compounds. Credit: 10.3390/ijms23010393
Virtual screening, a computational marvel, is deployed to sift through vast libraries of compounds, identifying potential drug candidates with remarkable speed and cost-effectiveness. In contrast to traditional experimental methods, which might take years to screen a single compound, virtual screening expedites the identification of promising candidates. This acceleration in the early stages of drug discovery is a testament to the efficiency afforded by computational approaches.
Genomic medicine
Genomic medicine emerges as a transformative frontier in healthcare, leveraging an individual's genetic information to revolutionize the way medical interventions are tailored. This personalized approach to healthcare begins with the identification of genetic variations that wield influence over disease susceptibility. By meticulously scrutinizing the individual's genetic landscape, genomic medicine has the power to unveil inherent genetic predispositions. This predictive capability propels preventive measures and early interventions, ushering in an era where healthcare is not just reactive but anticipatory.

At the forefront of genomic medicine lies the realm of pharmacogenomics, an intricate study of how an individual's genetic makeup shapes their response to drugs. This discipline delves into the interplay between genetic factors and drug metabolism, aiming to optimize drug efficacy while mitigating adverse reactions. Through the analysis of genetic information, researchers can predict an individual's likely response to specific medications, enabling healthcare providers to tailor drug regimens that are not only more effective but also carry minimized risks of side effects.
The applications of genomic medicine extend into the intricate domain of personalized cancer therapy, where the analysis of a patient's genetic makeup becomes pivotal. By unraveling the genetic mutations that propel the growth of cancer cells, physicians gain critical insights into the unique molecular signatures of the disease. Armed with this knowledge, they can craft targeted therapies designed to selectively attack cancer cells while sparing healthy ones. This precision in treatment not only enhances efficacy but also minimizes the collateral damage often associated with traditional cancer therapies, marking a paradigm shift in the battle against cancer.
In the real-world application of personalized cancer therapy, patients become active participants in their own healthcare journey. Through the lens of genomic medicine, treatment plans are not generic but rather finely tuned to the specific genetic characteristics of each patient's cancer. This approach not only holds the promise of better outcomes but also ushers in a new era where medical interventions are as unique as the individuals they seek to heal.
Disease diagnostics
Computational biology and bioinformatics delve into the intricate world of protein interactions, identifying pivotal biomarkers for diseases. Understanding the complex interplay between proteins unveils potential drug targets, fostering the development of more efficacious treatments. The integration of computational biology and bioinformatics in medical imaging analysis has enabled the early identification of disease-related patterns. By scrutinizing medical images, these technologies contribute to the development of diagnostic tools that facilitate swift and accurate disease detection. This, in turn, facilitates the formulation of personalized treatment strategies tailored to the unique characteristics of each patient.
Evolutionary Biology
One pivotal technique that has emerged as a cornerstone in this exploration is phylogenetics. Through the construction of evolutionary trees, phylogenetics meticulously maps out the intricate relationships between different species. This visual representation serves as a roadmap, elucidating the branching points and shared ancestry, enabling us to trace the evolutionary trajectories of organisms and decipher the interconnectedness of life forms across time.
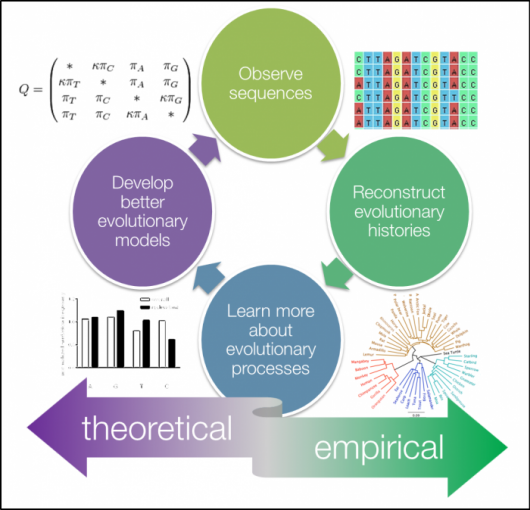
Molecular clocks stand as another formidable tool within the evolutionary biologist's arsenal. By estimating mutation rates, these clocks unveil the temporal dimensions of evolution, allowing us to discern the pace at which various species have undergone genetic transformations. This temporal understanding is crucial in deciphering not only the chronology of evolutionary events but also in unraveling the selective pressures that have driven these genetic changes.
Delving deeper into the genetic landscape, computational models offer insights into genes under positive selection. This facet provides a window into the mechanisms of natural selection that have sculpted the genetic makeup of different species. Identifying genes subject to positive selection unveils the adaptive forces at play, painting a vivid picture of how organisms evolve to thrive in their environments.
Beyond the individual gene level, computational approaches extend their reach to ancestral reconstructions. These reconstructions provide a captivating glimpse into the evolutionary history of various species, allowing us to visualize the common ancestors and pivotal transitions that have shaped the diversity of life forms we observe today. This temporal reconstruction serves as a narrative thread, weaving together the intricate stories of biological lineages.
Genome comparisons represent yet another dimension of computational exploration, unveiling conserved genes that form the genetic basis of different traits. This comparative genomics approach goes beyond mere sequence alignments, offering a nuanced understanding of the genetic elements that endure across evolutionary time scales. In essence, it unveils the genetic blueprints that underpin the diversity of traits observed in different organisms.
In the context of public health, computational tools extend their utility to epidemiological modeling. By studying the spread of diseases, these models provide valuable insights into the dynamics of contagion, aiding our understanding of how diseases propagate through populations. This knowledge, in turn, informs strategies for disease control and prevention, contributing to the arsenal of tools available for managing public health crises.
Systems Biology
Systems biology engages in network analysis, dynamic simulations, and the integration of multi-omics data, all aimed at providing a holistic understanding of the complex interactions within biological systems. Two prominent computational methods employed in simulating dynamic processes within biological systems are ordinary differential equation (ODE) modeling and agent-based modeling. ODE modeling is particularly adept at representing systems governed by sets of differential equations, offering a quantitative depiction of their behavior. Conversely, agent-based modeling focuses on individual agents and the rules governing their behavior, providing insights into complex systems. Both methods find extensive application in systems biology, where they have been instrumental in modeling a diverse array of biological systems.

In the pursuit of predicting cellular behaviors in metabolic networks, constraint-based modeling emerges as a powerful computational method. By employing this approach, researchers can forecast how cells respond to varying environmental conditions, a capability crucial for optimizing bioprocesses. The versatility of constraint-based modeling is evident in its successful application across various biological systems, playing a pivotal role in optimizing bioprocesses across diverse industries. Its predictive capabilities have proven invaluable in enhancing our ability to manipulate and control cellular functions, contributing significantly to advancements in biotechnology.
Agriculture
In the 21st century, the significance of bioinformatics in the context of crop enhancement has surged, particularly in the wake of milestones like the completion of the human genome project and analogous initiatives focused on crop plants. Bioinformatics has evolved into a pivotal tool, empowering researchers to not only archive and retrieve biological data but also delve into multifaceted -omics data types, such as genomic, proteomic, transcriptomic, and metabolomic information. This comprehensive data analysis has unraveled the intricacies of crop genetics, unveiling the underlying genes responsible for coveted traits such as stress tolerance and disease resistance.
Figure 8
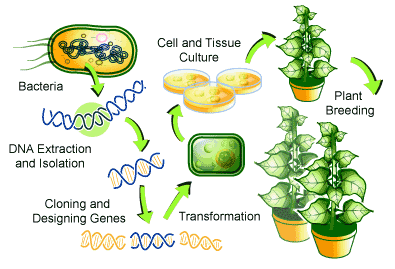
The process of genetic modification through isolation of a gene and insertion into the genetic sequence of a host organism. Credit: Water For All.
The integration of computational biology and bioinformatics into crop improvement strategies has yielded a crop revolution. By leveraging bioinformatics tools, scientists and plant breeders have identified sequence variants in biomass-centric crop species, enhancing biomass production and fortifying resistance. Moreover, the advent of high-throughput omics technologies has propelled plant breeding into a new era, facilitating the rapid advancement of crop varieties with superior yield performance and heightened resilience to the evolving challenges posed by climate fluctuations, pests, and diseases.
In concrete terms, this collaborative approach has manifested in the creation of novel crop varieties that exhibit robust resistance to pests and diseases. Through the judicious use of bioinformatics, researchers have been able to pinpoint specific genetic markers associated with desirable traits, providing a targeted and efficient means of crop enhancement. The impact of these advancements extends beyond immediate gains in food production, offering a sustainable solution that curtails reliance on pesticides, thereby contributing to environmentally conscious agricultural practices.
Challenges
Computational Biology stands at the forefront of scientific innovation, significantly influencing the biological sciences. Despite its contributions, the field grapples with several challenges that necessitate strategic solutions to propel its progress and application.
- Data Volume: The continuous surge in biological data, encompassing vast genomic, transcriptomic, and proteomic datasets, presents formidable challenges in storage, management, and processing. The sheer magnitude of this data calls for scalable solutions capable of handling such voluminous datasets effectively. Addressing this challenge is crucial for maintaining the momentum of research within the field.
- Data Accuracy: The integrity and precision of biological data are paramount, as errors can propagate throughout analyses, leading to misguided conclusions. The development of robust data validation and quality control methods is imperative to instill confidence in computational biology findings. Enhancing accuracy not only safeguards the integrity of research but also fosters trust in the broader scientific community.
- Data Integration: The heterogeneity of biological data, stored in diverse formats, poses a formidable obstacle to seamless integration. Successful amalgamation of data from disparate sources, spanning genomics, clinical records, and environmental factors, demands standardized formats and interoperable tools. Strides in this area are pivotal to extracting comprehensive insights from multifaceted datasets.
- Computational Resources: The execution of large-scale computations, essential for tasks like molecular simulations and genome-wide association studies, necessitates substantial computational resources. Overcoming the challenge of ensuring access to high-performance computing infrastructure, particularly for smaller research institutions, is integral to maintaining the field's inclusivity and accelerating advancements.
- Interdisciplinary Collaboration: Achieving effective collaboration between biologists, computer scientists, mathematicians, and statisticians is fundamental for the success of computational biology. Bridging the gap between these diverse disciplines and fostering a culture of interdisciplinary teamwork remains a challenge. Encouraging collaboration is essential for addressing complex biological questions that require diverse expertise.
To confront these challenges head-on, computational biology researchers are pioneering innovative solutions. Cloud computing platforms like Amazon Web Services and Google Cloud Platform offer scalable and cost-effective solutions for data storage and processing, alleviating some of the burden associated with data volume. Machine learning algorithms are being actively developed to enhance data accuracy and streamline quality control processes.
Standardization of data formats, exemplified by the adoption of formats such as FASTQ and BAM, is streamlining the integration of heterogeneous biological data. Furthermore, initiatives like the National Institutes of Health’s Big Data to Knowledge (BD2K) program are playing a crucial role in fostering interdisciplinary collaboration, providing a framework for researchers to collectively tackle complex biological challenges.
Scientific journals
In 2024, Clarivate has indexed 62 journals whose scope primarily encompasses computational biology. Journals with broader scope such as Science and Nature also contain computational biology research, so this number is much higher.
List of journals
- Acta Biotheoretica
- Algorithms for Molecular Biology
- Annual Review of Biomedical Data Science
- Bio-Algorithms and Med-Systems
- Biodata Mining
- Bioinformatics
- Biometrical Journal
- Biometrika
- Biostatistics
- Biosystems
- BMC Bioinformatics
- Briefings in Bioinformatics
- Bulletin of Mathematical Biology
- Cancer Informatics
- Computers in Biology and Medicine
- Current Bioinformatics
- Current Opinion in Systems Biology
- Database-The Journal of Biological Databases and Curation
- Evolutionary Bioinformatics
- Frontiers in Computational Neuroscience
- Frontiers in Neuroinformatics
- Genetic Epidemiology
- IEEE Journal of Biomedical and Health Informatics
- IET Systems Biology
- Infectious Disease Modelling
- In Silico Plants
- Interdisciplinary Sciences-Computational Life Sciences
- International Journal for Numerical Methods in Biomedical Engineering
- International Journal of Biomathematics
- International Journal of Biostatistics
- International Journal of Data Mining and Bioinformatics
- Journal of Agricultural Biological and Environmental Statistics
- Journal of Bioinformatics and Computational Biology
- Journal of Biological Dynamics
- Journal of Biological Systems
- Journal of Biomedical Semantics
- Journal of Computational Biology
- Journal of Computational Neuroscience
- Journal of Integrative Bioinformatics
- Journal of Mathematical Biology
- Journal of Molecular Graphics & Modelling
- Mathematical Biosciences
- Mathematical Biosciences and Engineering
- Mathematical Medicine and Biology-A Journal of the IMA
- Mathematical Modelling of Natural Phenomena
- Medical & Biological Engineering & Computing
- Molecular Informatics
- NAR Genomics and Bioinformatics
- Network Modeling and Analysis in Health Informatics and Bioinformatics
- NPJ Systems Biology and Applications
- PLOS Computational Biology
- Quantitative Biology
- Research Synthesis Methods
- SAR and QSAR in Environmental Research
- Statistical Applications in Genetics and Molecular Biology
- Statistical Methods in Medical Research
- Statistics and Its Interface
- Statistics in Biopharmaceutical Research
- Statistics in Biosciences
- Statistics in Medicine
- Theoretical Population Biology
- Wiley Interdisciplinary Reviews-Computational Molecular Science
Acknowledgements
Much of this material has be remixed, adapted, and summarized from the following sources.
- omicstutorials
- Auslander, N., Gussow, A. B., & Koonin, E. V. (2021). Incorporating machine learning into established bioinformatics frameworks. International journal of molecular sciences, 22(6), 2903. doi: 10.3390/ijms22062903
- Lam, S., Doran, S., Yuksel, H. H., Altay, O., Turkez, H., Nielsen, J., ... & Mardinoglu, A. (2021). Addressing the heterogeneity in liver diseases using biological networks. Briefings in Bioinformatics, 22(2), 1751-1766. doi: 10.1093/bib/bbaa002
- Pakhrin, S. C., Shrestha, B., Adhikari, B., & Kc, D. B. (2021). Deep learning-based advances in protein structure prediction. International Journal of Molecular Sciences, 22(11), 5553. doi: 10.3390/ijms22115553
- Kralj, S., Jukič, M., & Bren, U. (2021). Commercial SARS-CoV-2 Targeted, Protease Inhibitor Focused and Protein–Protein Interaction Inhibitor Focused Molecular Libraries for Virtual Screening and Drug Design. International Journal of Molecular Sciences, 23(1), 393. doi: 10.3390/ijms23010393